AI
Claude Code/OpenClaw access Database MCP service
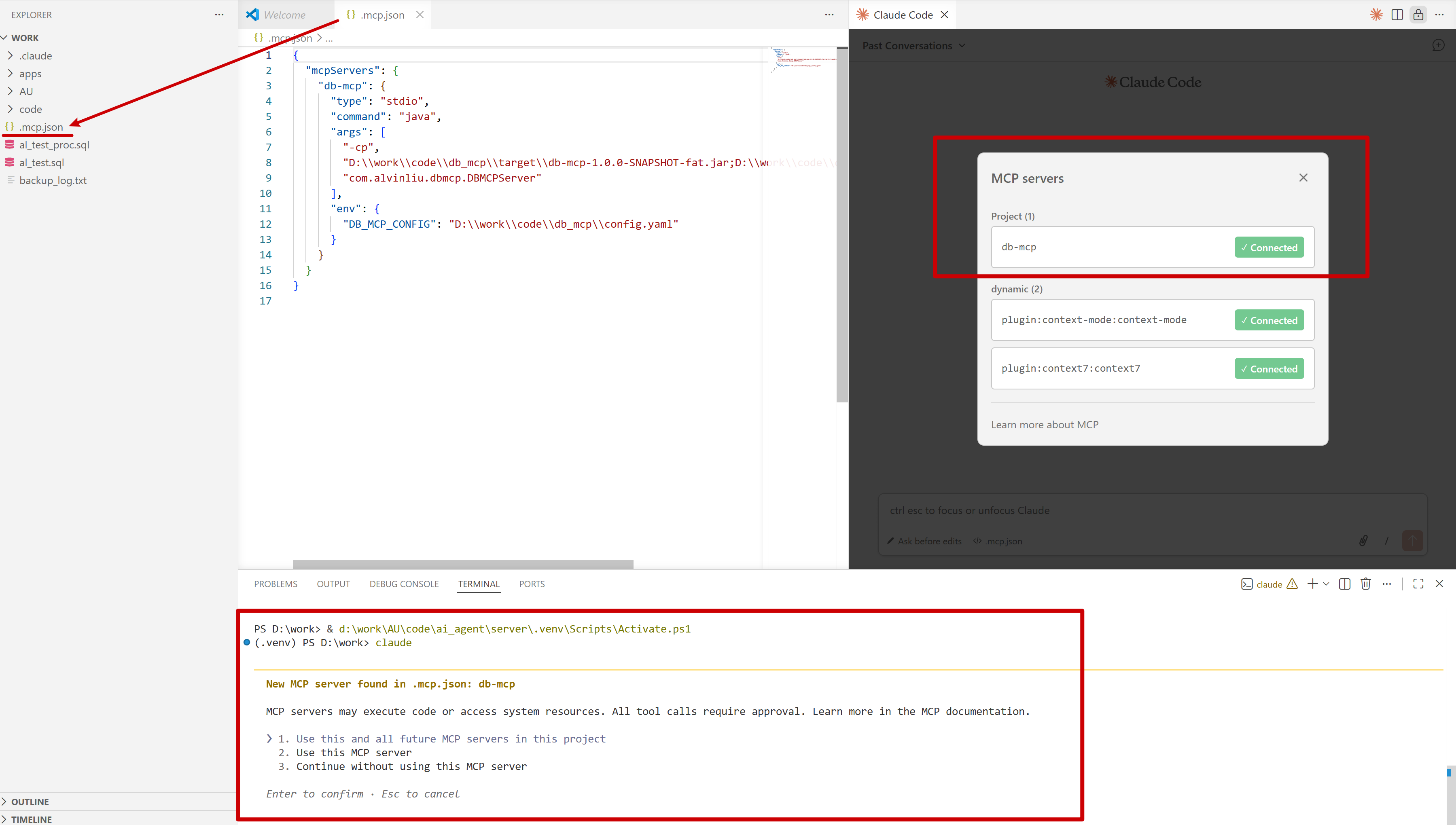
I am proud to announce that my Database MCP Server now supports most AI IDEs, enabling seamless connections to a wide range of databases. A general-purpose MCP server that lets any MCP-compatible AI client (Cursor, Claude Code, OpenClaw, etc.) connect to any JDBC-supported database (Oracle, MySQL, Read more